Blog

From internship to authorship: one student’s unique journey in ATLAS
Lukas Kretschmann, a physics student at the University of Wuppertal in Germany, shares his journey in the ATLAS Collaboration – which began as a high-school student!
Blog |

ATLAS Week: through the eyes of students
ATLAS Week is an opportunity for young physicists to present and discuss their work. ATLAS students Sarah and Bruna were at the last ATLAS Week in Vancouver, Canada, and share what the experience was like for them.
Blog |

ATLAS & CMS Physicists Recover Lost Higgs Boson
Scientists working on the Large Hadron Collider at CERN breathed a sigh of relief today, as the world-renowned Higgs boson returned to its showcase in the heart of the laboratory.
Blog |

Developing the ATLAS End-Cap Toroids: a personal history
Former ATLAS engineer Elwyn Baynham shares his experience as part of the team developing the ATLAS End-Cap Toroids. His story paints a personal picture of the history of these incredible magnets.
Blog |

Building an ATLAS gingerbread wonderland
When I received an email from the ATLAS outreach coordinators in October 2021, asking if I would help them make an ATLAS-inspired gingerbread village for this year’s card, I couldn’t refuse an opportunity for another fun “Physics Cakes” project.
Blog |

ATLAS without Frontiers
For several years, the ICTP Physics Without Frontiers (PWF) programme has been heavily involved with outreach activities to inspire, train and educate young and motivated physics students worldwide. Several members of the ATLAS Collaboration very active in this programme.
Blog |
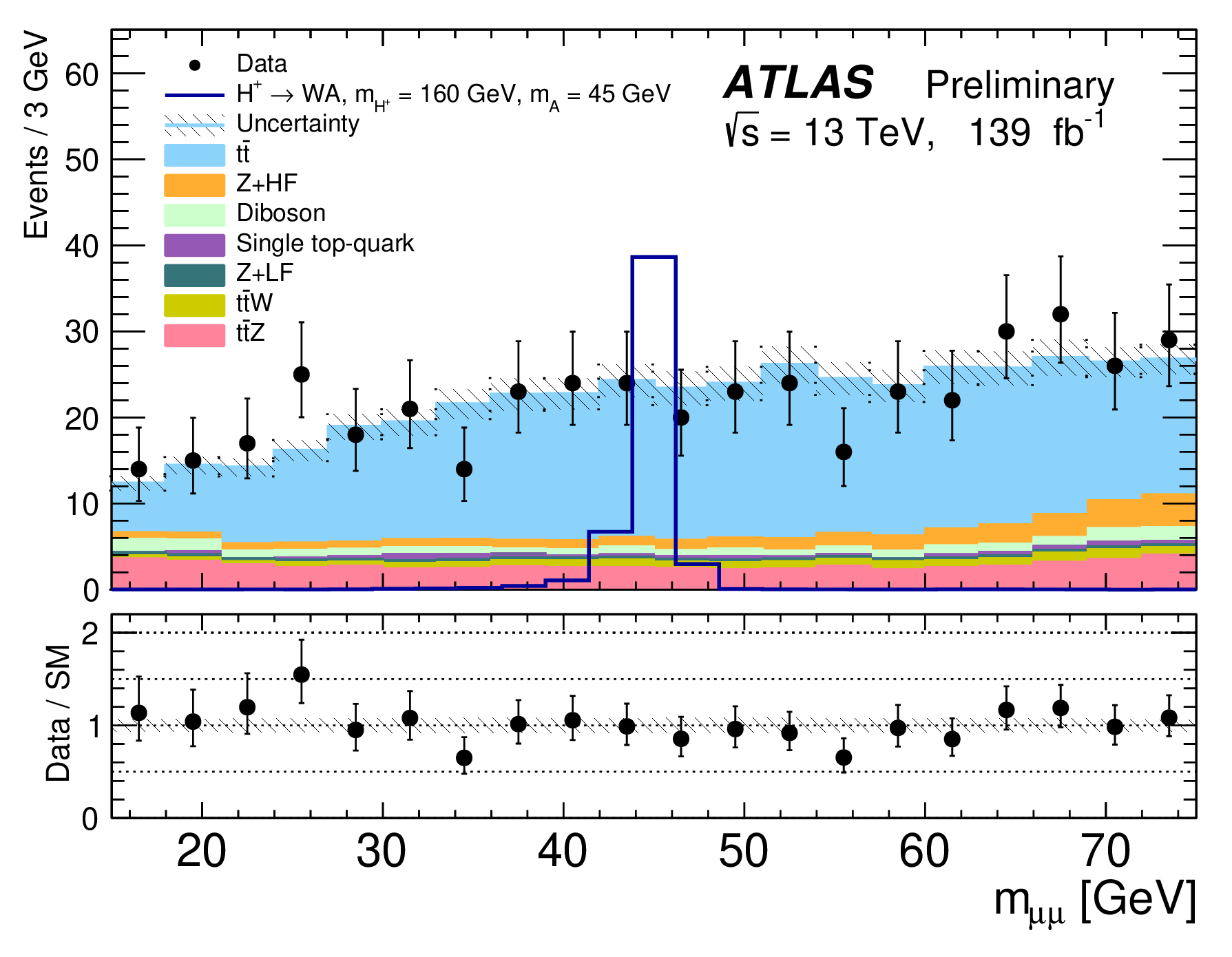
ATLAS pushes forward the search for a charged Higgs boson
ATLAS physicists Florencia Daneri and Waleed Ahmed share the latest news from the Charge-Higgs@LHC workshop, which took place online August 30-31, 2021.
Blog |
Building community in virtual events
Since 2017, the ATLAS Early Career Scientist Board (ECSB) and Analysis Software Tutorial organisers have been teaming up to run a week-long introductory event for new ATLAS members. Induction Day welcomes new members to the collaboration by giving them an overview of the plethora of activities that take place within the ATLAS Collaboration.
Blog |

Planning an event during a pandemic
At the ATLAS Early Career Scientist Board (ECSB), we have also had to adapt in order to best represent and assist the early career scientists in our collaboration. One of the biggest changes was moving all of our events in the second half of 2020 to be entirely virtual.
Blog |

Teaching university students with real ATLAS data
ATLAS PhD student Meirin Oan Evans explores how the University of Sussex is incorporating ATLAS Open Data into their teaching – and shares his experience using this incredible resource.
Blog |

Exploring the “coolest” mock-up
It was in 2014, just a few months after my transition from ALICE to ATLAS, that I saw the mock-up for the first time: a full-scale wooden reproduction of the central portion of the ATLAS experiment, measuring some 8 metres high and wide.
Blog |

Connecting during COVID-19: Updates from the (physically but not socially distanced) Early Career Scientist Board
As a community, we need to stay in contact, remain motivated and learn from each other's experiences. The work-from-home situation is one to which everyone has to adjust, balancing personal and professional lives, while accepting the effect of the ongoing pandemic on society. Despite these challenges, the ATLAS Early Career Scientist Board (ECSB) developed a series of events to boost the morale of the ECS community and to help people connect, even when they are sitting miles away from each other. I joined the ATLAS ECSB in March 2020, and to be honest, it has felt great to be a part of something that makes a difference in people’s lives – even if it’s just to laugh together.
Blog |

You want me to present a poster…. remotely?
Though an academic affair, poster sessions are also an opportunity to network and socialise with colleagues. Typically, a large hall will be filled with rows of poster stands, their authors standing anxiously beside them, anticipating whatever question may be posed by a passer-by. Finger food and drinks are usually served. Sometimes these encounters lead to in-depth discussions about a new result but, more often than not, they just serve as ice-breakers for would-be colleagues, or a kind of “physics buffet” for conference attendees to sample subjects outside their specialization. Could such an experience be recreated in an online conference?
Blog |

Serving up new winter recipes with the ATLAS Early Career Scientist Board
In 2019, I joined the ATLAS Early Career Scientist Board (ECSB): a special advisory group dedicated to assisting the ATLAS Collaboration in building an environment where the full scientific potential of scientists at the start of their career can be realised. The board organises several activities for the ATLAS community (you may have seen all of our summer activities described in this blog). I was actively involved in the winter activities. They were all fantastic experiences to improve social relationships in a 5000-people collaboration.
Blog |

Sharing the Excitement of ATLAS
This past week, I grabbed a last-minute opportunity to wander about and take in the beauty of my favourite particle physics detector. Located 100 meters under the French/Swiss border near Geneva, ATLAS is always a marvel to see and to explore. Although I have hosted hundreds of visits by its side, I never tire of the view and inevitably pull out my phone or camera to photograph it, yet again.
Blog |

New ATLAS members, welcome on board
This summer was rich with events regularly organised by the ATLAS Early Career Scientists Board (ECSB): Induction Day, Career Q&A and the Ice Cream event. The ECSB is a special advisory group dedicated to assisting the ATLAS Collaboration in building an environment where the full scientific potential of young scientists can be realised. It consists of seven early career scientists, representing various career levels, nationalities, genders and home institutions. I have been in the thick of things as a new member of the ECSB and had a lot of new experiences. Each event was full of fantastic people and brought to its participants tonnes of useful information.
Blog |

Ten days of Trigger and Data Acquisition at ISOTDAQ
This April marked the 10th anniversary of the International School of Trigger and Data Acquisition (ISOTDAQ). It was a fantastic event that united researchers in physics, computing and engineering, ranging from undergraduate students to post-doctoral scientists. The goal of the school was to teach the "arts and crafts" of triggering and data-acquisition for high-energy physics experiments through a series of lectures and hands-on laboratory exercises.
Blog |

Boosting high-energy physics education around the world with ATLAS Open Data
Since the beginning of ATLAS, collaboration members have devoted hours, days, weeks and months teaching High Energy Physics (HEP) to anyone willing to listen. But sometimes those willing to listen do not have the means, especially when oceans and continents separate them from our experiment in Geneva. How can we overcome these geographical distances to allow anyone interested in HEP to learn?
Blog |

International conferences: interesting physics & instant excitement
What a start it's been to my first conference! I was lucky enough to join the 39th International Conference on High Energy Physics (ICHEP), the biggest conference in High Energy Physics. About 1000 physicists are currently gathered in Seoul, presenting results from all across the field. Getting to visit South Korea plus hearing about cutting-edge physics sounded like a 5-star recipe to me!
Blog |
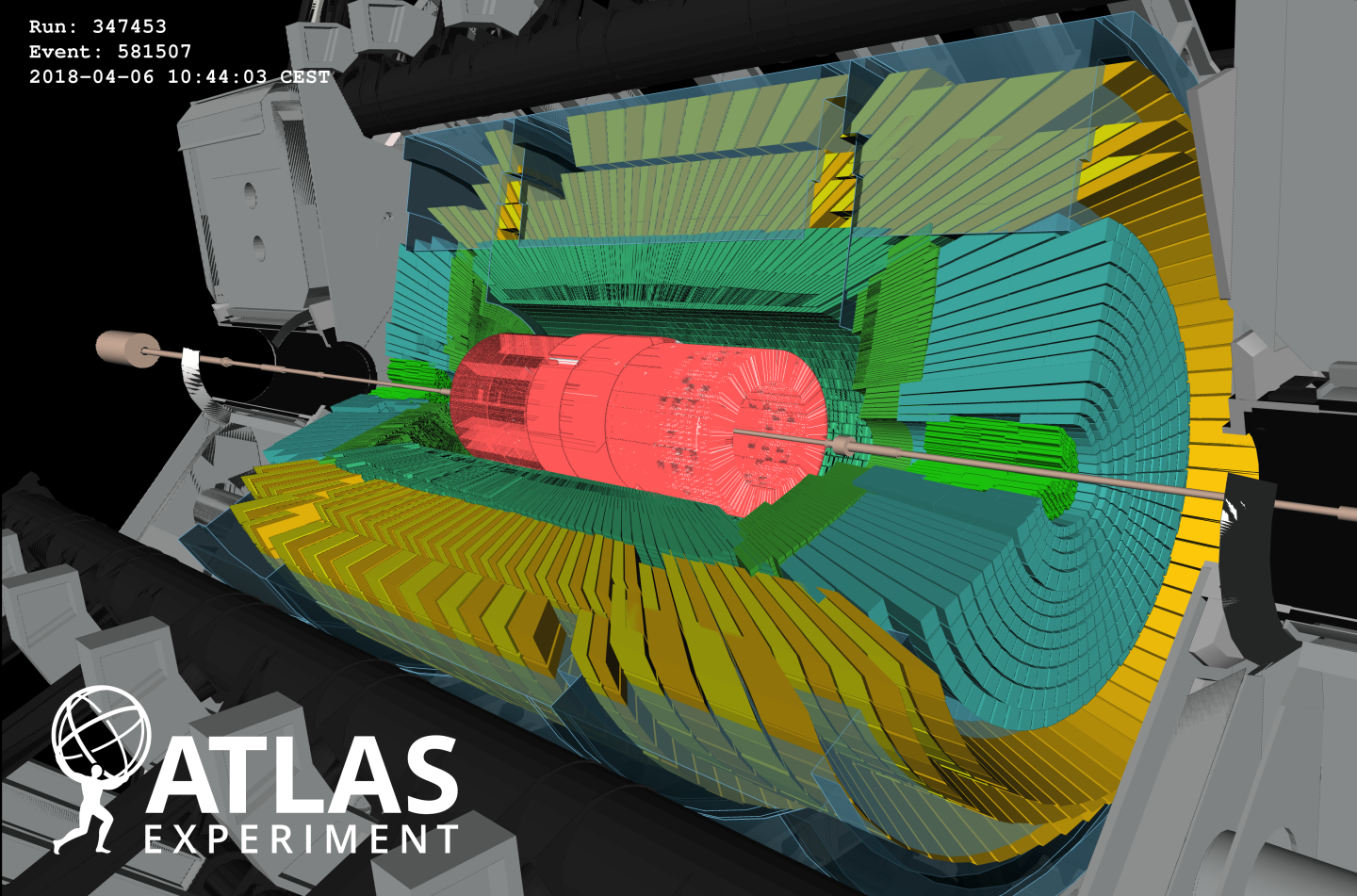
Waiting for physics: Stable beams!
Following the first “beam splash” tests in early-April, the ATLAS experiment awaited the next milestone on the road to data-taking: "stable beams". This is when the LHC proton beams are aligned, squeezed, focused and finally steered to collide head-to-head. It is an important test, as it allows us to verify that the collision mechanism is ready to take data that are good for physics studies.
Blog |
Waiting for physics: Splashing beams
Each year, around mid-spring, the giant LHC accelerator wakes up from its winter maintenance and gets ready for a new feverish period of data taking. But before smashing protons once again, some tests have to be done, to check that everything is in order and that the machine can accelerate and collide particles properly, as it did before the shutdown.
Blog |

Angels and Teachers
I met beautiful people in Los Angeles earlier this month: smart, talented students, all destined for great careers. They welcomed me to their high schools and their after-school programmes, all well-equipped with computing, electronics, a robotics lab and, above all, a brilliant staff of teachers.
Blog |

Reaching out across cultures
This past Spring, I had the opportunity to travel to Taos, New Mexico, USA, to work with artist Agnes Chavez, on one of her “Projecting Particles” workshops. Her innovative programme aims to develop STEM (Science, Technology, Engineering, Math) skills in students aged 8 and up, employing a mixture of science education and artistic expression. It is a winning combination for everyone involved.
Blog |

The art of physics
I have been doing some work with artists recently. Not that I’m planning a career change, you know: I just love to talk about my research to anyone who is prepared to listen, and lately it’s been with artists. Ruth Jarman and Joe Gerhardt, aka Semiconductor, are internationally renowned visual artists who in 2015 won the Collide@CERN Ars Electronica Award and spent a two-month residency at CERN. Like myself, they live in Brighton, which is also home to the University of Sussex, where I work.
Blog |

How to run a particle detector
If you are interested in particle physics, you probably hear a lot about the huge amount of data that is recorded by experiments like ATLAS. But where does this data come from? Roughly speaking: first you have to plan, build and maintain an experiment and in the end you need people to analyse the data you’ve recorded. But what happens in between? What happens in the day-to-day life of people in the ATLAS control room, who are responsible for keeping all that great data coming?
Blog |